Highlights
Need
Automate remittance notes processing, reducing manual efforts and eliminating unprocessed data
Solution
App with AI capabilities for document recognition and automated remittance notes processing
Results
70%
recognition precision
8–9x
automation of manual remittance notes processing
Partnering with HQSoftware, the customer was able to automate the process of remittance notes recognition with a precision of 70%. By digitizing the workflow, the company enhanced document processing by 8–9 times. The automation allowed for parallel processing of 12–15 documents per minute, while it previously took 5–10 minutes to aggregate a single remittance note.
Looking for similar solutions or something unique to your needs?Contact us today! We’re happy to explore your needs!
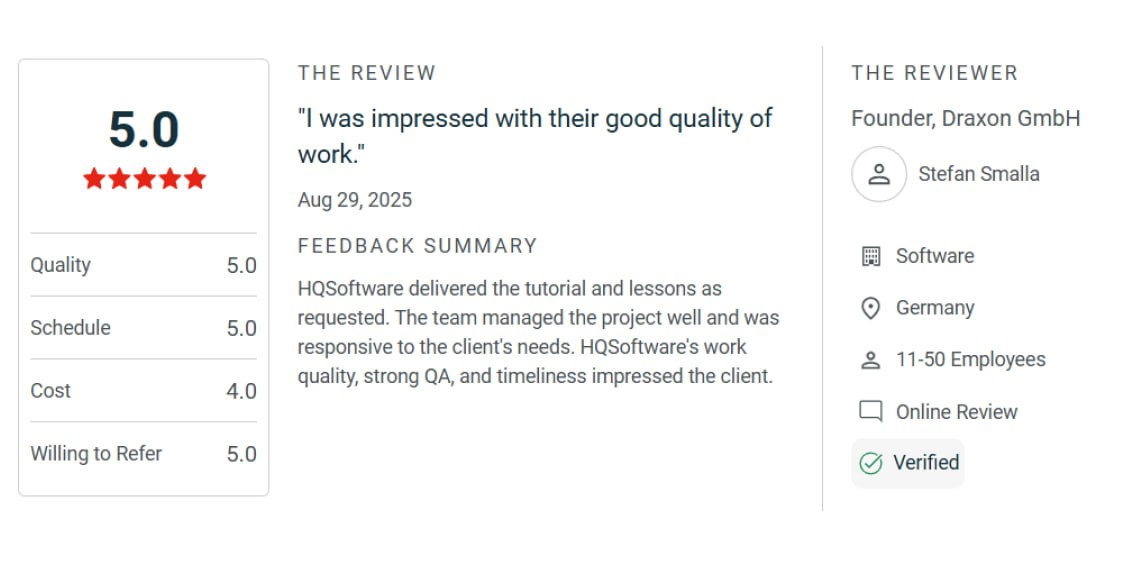
Victoria Rokash
Business Development Manager

Customer
Based in the USA, the customer provides invoice and remittance notes processing services to healthcare organizations. Under the healthcare system of the USA, insurance is partly covered by the government and partly by the private insurance companies. The customer is engaged in aggregating the invoices and remittance notes submitted by medical institutions to estimate the share to be covered by the state and insurers.



Challenge
The submitted remittance notes — sent to the customer as scanned PDF documents — should be uploaded to the third-party system for further analysis and split. However, all the organizations used different templates to formalize and structure the documents, which significantly complicated the process of recognition. Furthermore, some documents were incomprehensible even to a human eye.
When the customer turned to HQSoftware, all the information available through the submitted remittance notes was added to the third-party database manually, which dramatically slowed down the processing and required a lot of staff to be engaged. This resulted in immense amount of documents left unprocessed over the period of four years.
Solution
Powered by machine learning, the delivered solution is an application that features a set of pre-trained templates capable of recognizing the information available through the submitted PDF remittance notes and organizing it into an e-form with editable fields. The solution supports a variety of cloud file hostings, such as Google Drive, Dropbox, etc., as well as can be customized to support any other hosting of choice.
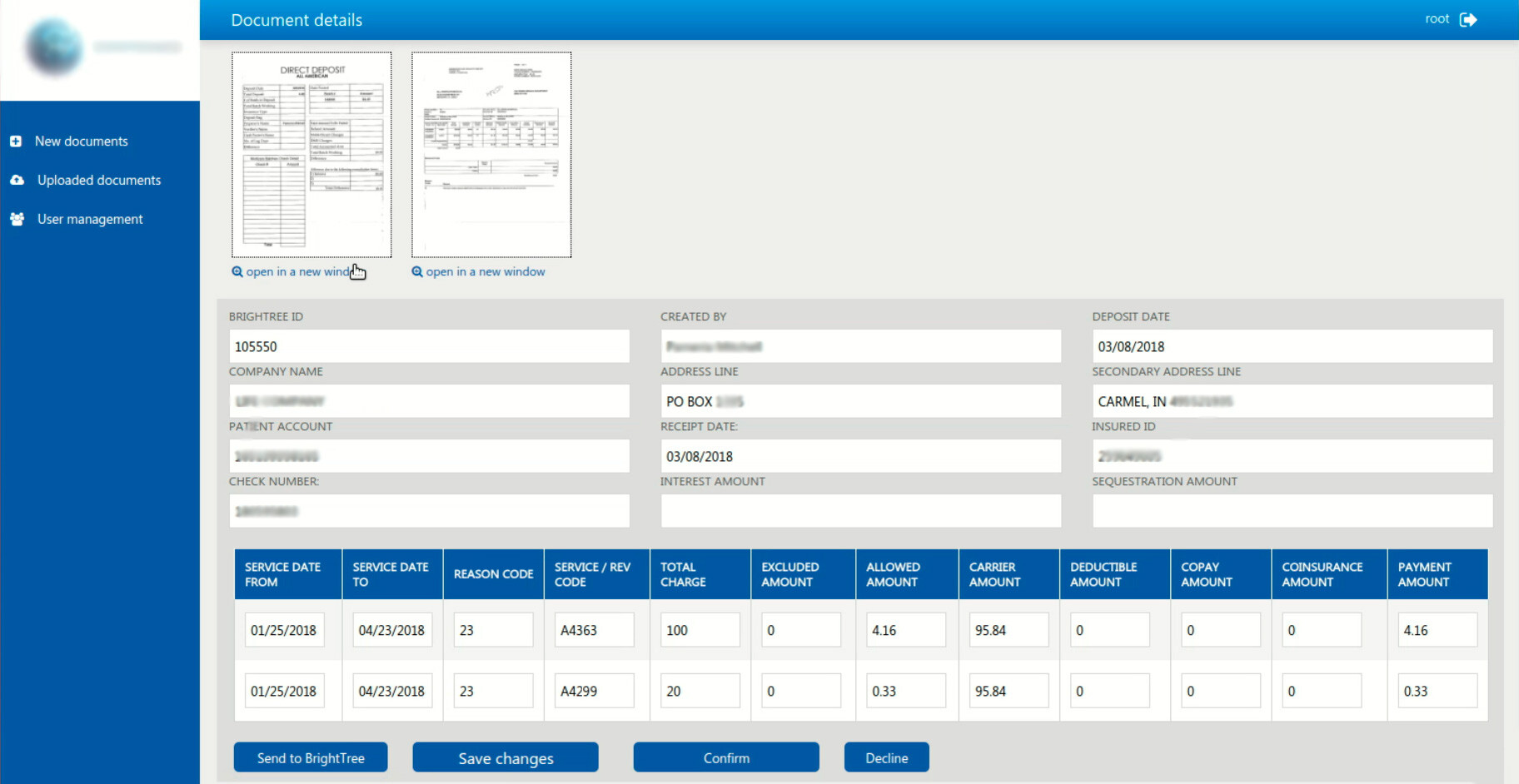
Once the documents are uploaded to the delivered application, it automatically transfers the data to the third-party system. However, this system did not have an API and was only accessible through a website. For this reason, developers at HQSoftware utilized Selenium WebDriver to emulate user interaction with a website and enable upload in the background mode.
Employing Tesseract OCR, our engineers ensured that the system recognized and distinguished between five types of document templates with precision of 70%. To achieve such high result, experts at HQSoftware created a collection of most common templates submitted by healthcare institutions and performed up to 30 training iterations over a document type.
For the cases when an remittance note lacked some particular information, such as an address, our team delivered an algorithm that allowed for checking other remittance notes submitted by the organizations, matching the missing data with the appropriate institution, extracting the necessary information from the available documents, or removing the duplicates.
If the solution was unable to recognize the document, the system would transfer the file to a separate folder, mark it as for manual processing, and send notification to an administrator.
Read more about our data analytics services.
Check Out Other Works
See How We Approach Business Objectives


We are open to seeing your business needs and determining the best solution. Complete this form, and receive a free personalized proposal from your dedicated manager. Sergei Vardomatski Founder