Highlights
- Data gathering from multiple, inconsistent sources
- Tuned algorithms to differentiate between sources, prioritize them, and aggregate data with better precision
- Building profiles of unique passengers based on information processed
- High-load sustainability
Technologies Used: PostgreSQL, Python, Apache Airflow, SQLAlchemy, Flask, Alembic, Vagrant, GEvent, RabbitMQ, Pytest
Methodology: Agile
Looking for similar solutions or something unique to your needs?Contact us today! We’re happy to explore your needs!
Victoria Rokash
Business Development Manager

Customer
Based in Russia, S7 is the country’s second-biggest airline company. Flying to 91 destination points, the airlines have delivered its services to 9,5+ million passengers in 2016. The customer is a full member of the Oneworld alliance—the third largest global airline alliance in terms of passengers with 550+ million passengers carried in 2016.
S7 operates in 37 Russian cities, 13 cities in the Commonwealth of the Independent States, and in 14 other cities worldwide, including Frankfurt-am-Maine, Beijing, Seoul, Antalya, and Bangkok.
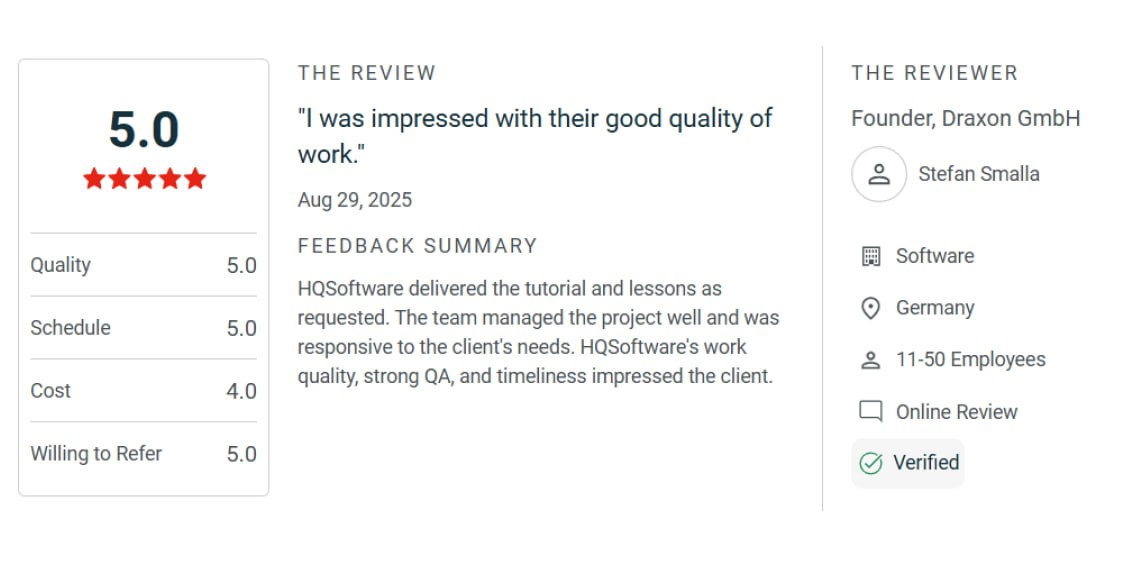


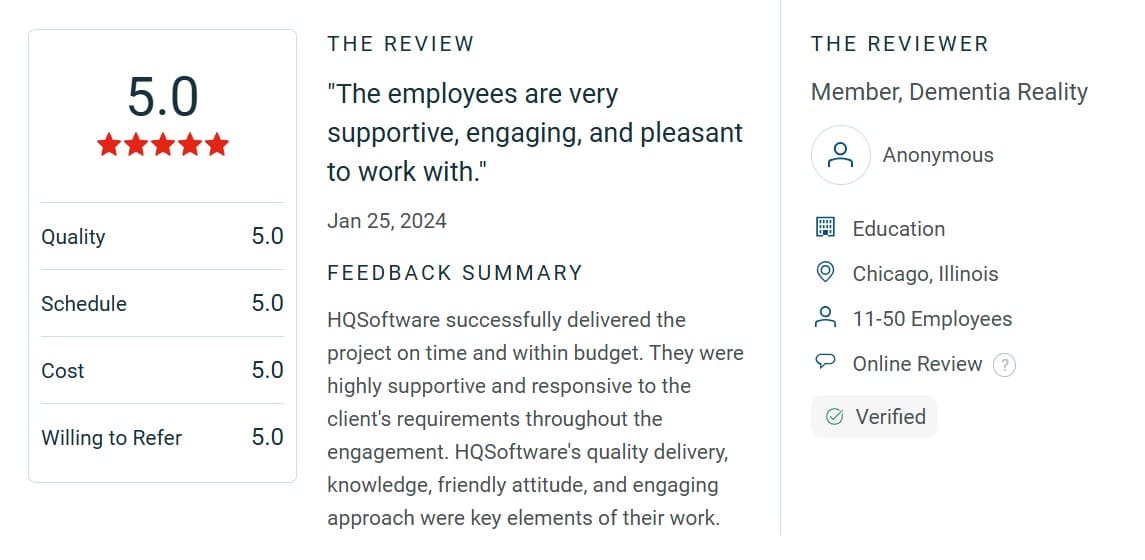

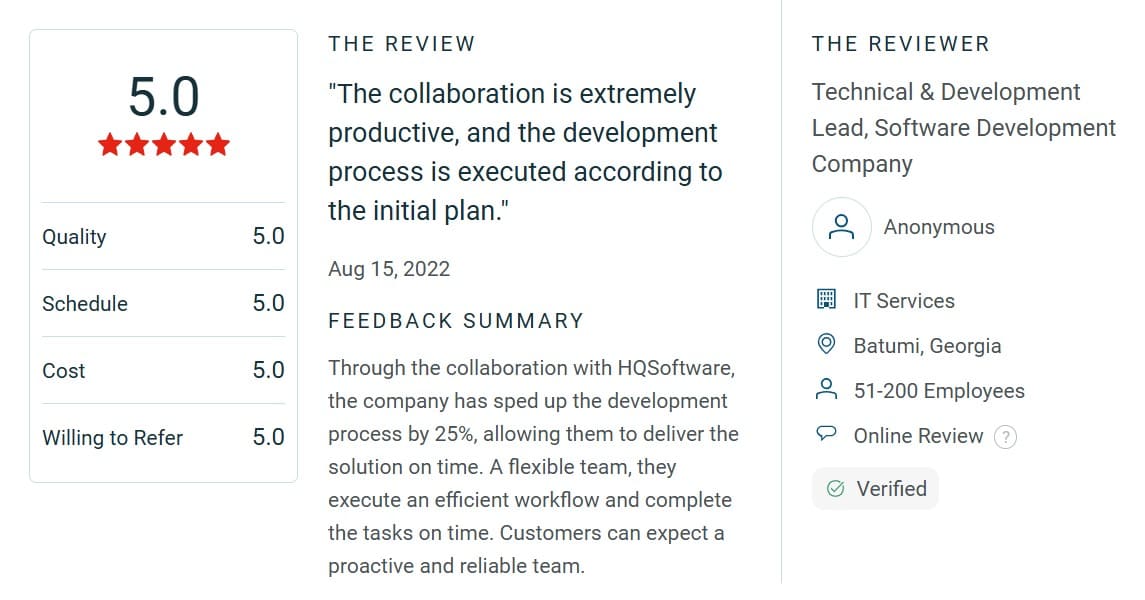
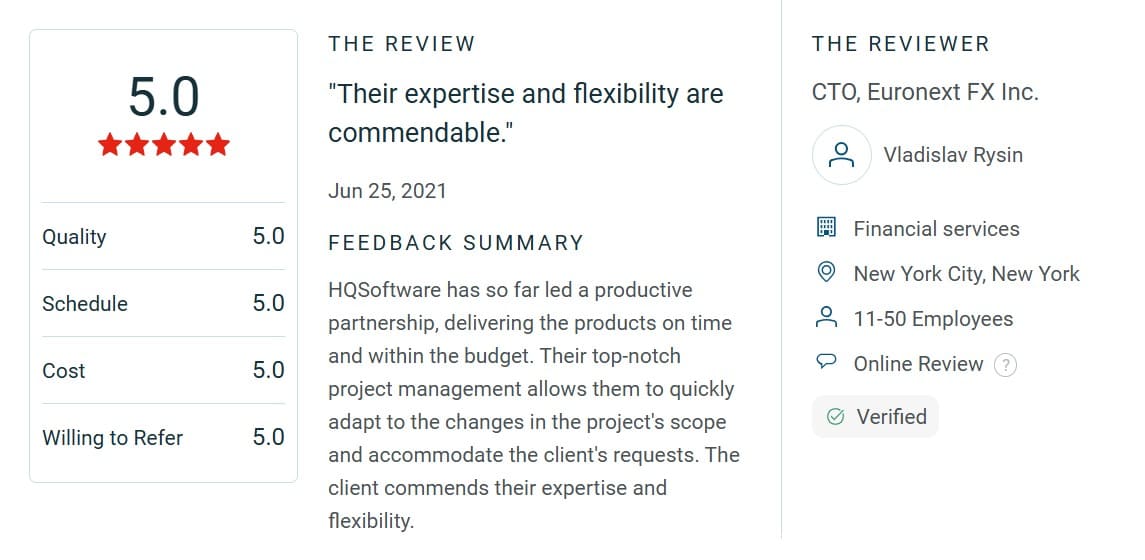
Need
Partnering with HQSoftware, S7 wanted to develop a system that would aid the company in building a profile of a unique passenger to improve customer service.
To generate such a profile, the information was gathered from multiple sources, each providing inconsistent and fragmentary data. So, there was a need to retrieve such data as:
- general personal information (gender, age, family status, etc.)
- passport data
- contacts
- flight bookings
- information about extra services booked
- correspondence history (any written communication with technical support)
The customer has already developed a module responsible for aggregating and cleansing data, as well as removing duplicates. However, the algorithms of prioritization used to further attribute the processed data to a particular passenger needed to be tuned.
Challenges
Under the project, the development team had to address the following issues:
- As long as the information was gathered from multiple sources, there was a need to ensure a faultless data upload. If an error occurs at any stage, data would not be uploaded to the next processing layer.
- There are certain difficulties associated with analyzing data while passengers provide incorrect personal information (e.g., any typos while submitting passport data), alter it, or add personal data of other passengers. With no algorithms that differentiated between the sources, it was hard to maintain data prioritization and, therefore, attribute personal information to a particular passenger.
- There was no test environment, which dramatically hampered the overall data aggregation.
- It was important to ensure that the delivered module would be able to sustain high loads.
Solution
Chosen by the customer, Apache Airflow was used to orchestrate the project’s workflows. It allowed for grouping tasks, tracking the progress, as well as working on the same tasks in parallel.
To guarantee that the system attributes personal information to a particular passenger, developers at HQSoftware tuned the algorithms of prioritization. So, there were enabled three levels of priority, which allowed to identify a passenger with better precision:
- The first level: A passenger booked and attended a flight.
- The second level: A passenger booked a flight, but did not attend it.
- The third level: A passenger has a personal account on the airlines’ website.
Then, our engineers modified the algorithms of cleansing, updating, and consolidating data to further improve precision. In addition, specialists at HQSoftware made it possible to differentiate between data sources, which minimized errors and significantly enhanced data processing.
On joining the project, our experts strongly advised on building a test environment. So, under the task, developers at HQSoftware ensured the system’s ultimate coverage with unit tests.
Using GEvent and Unicorn, our specialists enabled asynchronous processing of simple requests, thus making them independent of each other and preventing interlock in case of failure. To process complex requests, developers at HQSoftware implemented Celery that allowed for asynchronously executing job queues and evenly distributing the load.
To deliver further API sustainability, our team initiated test loading—by creating a Docker image that makes requests to a server—and made it possible to predict what loads the system is able to withstand.
Finally, experts at HQSowtfare helped to set up the development environment by integrating Python, Celery, RabbitMQ, and REST API with Docker.
Outcome
Collaborating with HQSoftware, S7 developed a system that extracts personal passenger data and builds unique profiles to improve the airline’s service. With tuned prioritization algorithms, the system now identifies the company’s clients with better precision. The delivered test environment helped to minimize errors and reduce the time spent on tracking and fixing bugs. The developed solution is also able to sustain high loads.
Check Out Other Works
See How We Approach Business Objectives


We are open to seeing your business needs and determining the best solution. Complete this form, and receive a free personalized proposal from your dedicated manager. Sergei Vardomatski Founder